Creating a “Cloudbox Mimic”
to map Rhizome growth choices, as a self-comprehended ‘hypotheses testing’ learning tool of ever-enlarging complexity
Would ‘asymmetric logic’ help machine-learners practice natural learning?
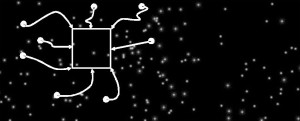 In 2014, I developed the Cloudboxing© thinking technique. Teaching myself to stitch together a set of cognitive cloud datapoints to create a place to study the building blocks of coding language, to learn exactly what code was and where it could be located in my data set. ie. Using my first cognitive language (Liquid Membraning) to translate coding language into the “building blocks” of Liquid Membraning language. See Project #5 at http://davehuer.com/solving-wicked-problems/
In 2014, I developed the Cloudboxing© thinking technique. Teaching myself to stitch together a set of cognitive cloud datapoints to create a place to study the building blocks of coding language, to learn exactly what code was and where it could be located in my data set. ie. Using my first cognitive language (Liquid Membraning) to translate coding language into the “building blocks” of Liquid Membraning language. See Project #5 at http://davehuer.com/solving-wicked-problems/
Lately, in between work, consulting, and venturing, I’ve been thinking about machine learning and Google’s DeepMind project, and wondering whether the “flatness” of programmed teaching creates limits to the learning process? For example…whilst reading the Google team’s “Teaching Machines to Read and Comprehend” article http://arxiv.org/pdf/1506.03340v1.pdf
Could we enlarge the possibilities, using spatial constructs to teach multidimensional choice-making?
 This could be a software construct, or a physical object [such as a transparent polymer block, where imaging cameras record choice-making at pre-determined XYZ coordinates to ensure the locations of choices are accurately mapped (especially helpful when there are multiple choices at one juncture)].
This could be a software construct, or a physical object [such as a transparent polymer block, where imaging cameras record choice-making at pre-determined XYZ coordinates to ensure the locations of choices are accurately mapped (especially helpful when there are multiple choices at one juncture)].
Encapsulating and organizing defined space for machine-learned self-comprehension. mimics the “cloudboxing” technique.
And, it mimics the natural self-programmed logic of self-learning…a novel teaching tool for the machine-learning entity:
- Creating a set of challenges through 3dimensional terrain that mimics pre-defined/pre-mapped subterranean tunnels
- Creating an opportunity to dimensionally map an emulated (or actual) entity growing through the tunnel system
- Studying the polar coordinates of the entity traversing the pre-defined space(s)
1) What about using a rhizome?
. . . Using a natural entity teaches a machine-learning entity to mimic natural learning.
Using a plant creates the possibility that we can map choice-making, using attractants such as H2O and minerals, as a mimic for conscious entities developing learned behaviour.
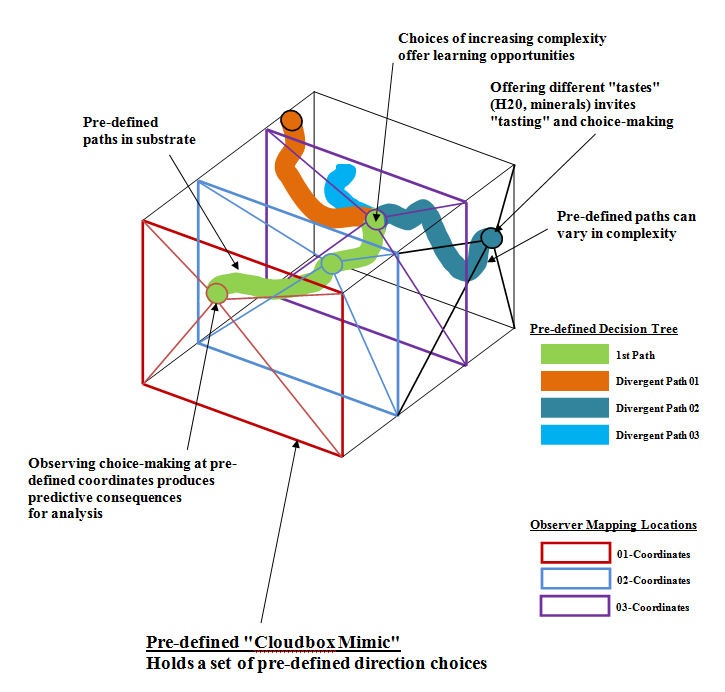
2) Once you have a defined baseline data set, could machines learn better if being blocked and shunted by an induced stutter?
Perhaps learning by stuttering and non-stuttering might produce interesting data?
By creating a stuttering event as the baseline, perhaps the program will use this to overcome obstacles to the learning process as well as the object of the lesson to learn to not stutter? This could produce a host of interesting possibilities and implications.
3) Things get incredibly interesting if the program eventually attempts to produce choice options outside the available options . . .
Note: These ideas continue the conceptual work of WarriorHealth CombatCare, re-purposing the anti-stuttering Choral Speech device SpeechEasy for Combat PTSD treatment. The research proposal for that work is here: https://www.researchgate.net/profile/David_Huer
Images:
Jiaogulan-Rhizome: Own work/Eigenes Foto by Jens Rusch, 29 August 2014 CC Attribution-Share Alike 3.0 Germany license.
Drawings: David Huer © 2014-2015


 * Software engineer at Alphabet (aka Google).
* Software engineer at Alphabet (aka Google).